
Active learning is the AI within RelativityOne’s analytics suite.
We have recently completed a large-scale review for an investigation. Time and cost were, as they always are, huge issues, so this was a fantastic project to show off the capabilities and spectacular accuracy of active learning.

Prioritised Review:
The case initially had over a million and a half documents. After filtering, keyword,
and concept searching, about 600,000 documents were left to review.
When you start a case, visualize that you have a huge mountain of documents to look at.
With Active Learning running in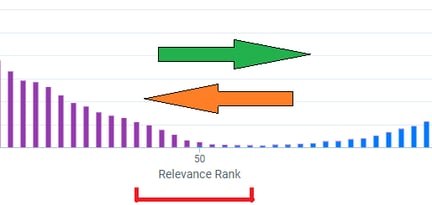 the background, the system watches and analyses the decisions that you make, right from the very first document that is reviewed and tagged relevant or not relevant.
the background, the system watches and analyses the decisions that you make, right from the very first document that is reviewed and tagged relevant or not relevant.
It says, “Hey! Let me go find some documents that look like this!”
So now, instead of having one big mountain, you have two smaller mountains one relevant and one not relevant.
The system is going to serve up the documents that it considers relevant first, based upon the decisions that you’ve been making and a percentile chance of the document being relevant; this is called a prioritised review.



