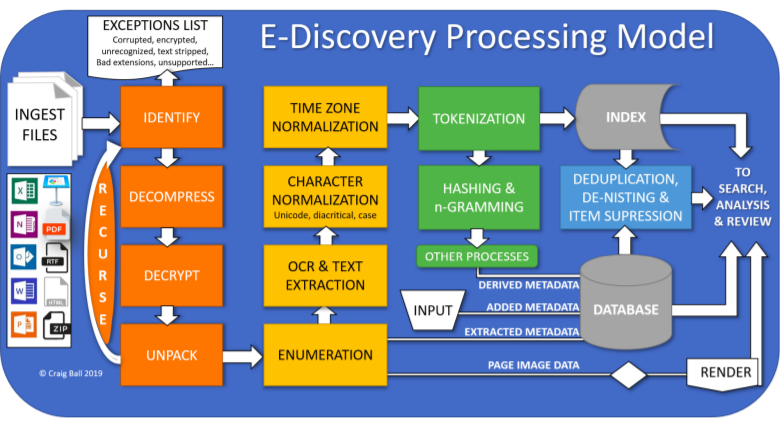
At the beginning of last week, the EDRM (Electronic Discovery Reference Model) published the final update to their “Guidelines for eDiscovery Processing”, a 40-page document adapted from Craig Ball’s “Processing in E-Discovery, A Primer” that aims to provide insight into the best practices for processing electronically stored information for the purpose of eDiscovery.
The Processing -> Review -> Analysis portion of the EDRM (see below) is without a doubt the most time-consuming and important phase of an eDiscovery project. It is where your data is culled (processing), the most relevant data extracted (review), and studied for its importance and impact on your case (analysis). As such, it is crucial to the smooth running of a project that these processes run without a hitch... Enter the processing best practices!
This guide has been produced as a resource to help those who regularly use processing products, supply processing products, support processing products, or who are new to the industry and want to learn more about processing. It is written to be educational to help the reader understand the basic steps of processing and focuses on the processing functions, ergo, no conclusions are drawn on specific processing products available.
Aside from the introduction, conclusion, and a glossary, the Guidelines for eDiscovery Processing are split into 5 sections for the 5 main pillars within processing. These are,
-
ESI Ingestion and File Extraction
-
Initial Filtering
-
Text, Metadata and Image Extraction
-
Processing Output
-
Reporting.
These sections then have several subsections as they expand on each specific topic such as Scanning for Viruses, Identifying and Removing Duplicate Files, and Language Detection.



